Mannerism Detection
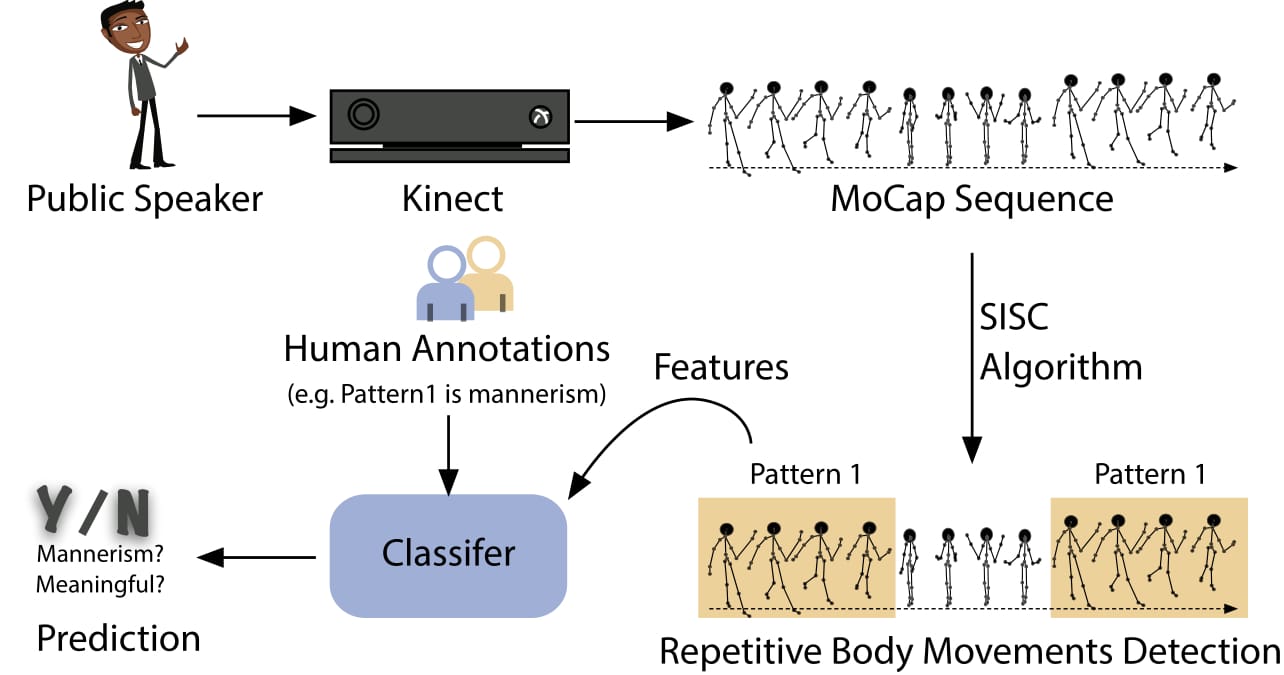
We use the Kinect to record and extract full body movements of the speakers in three-dimensional coordinates. At each time-instance, the signal consists of 60 (20 joints × 3 components—x, y, z) components. We reduce the signal input dimension with PCA. We use a shift-invariant sparse coding (SISC) algorithm to identify the commonly appearing patterns of body movements (Example). Online workers assess each pattern, along with verbal context, to decide if the pattern is just a mannerism or is a meaningful gesture.
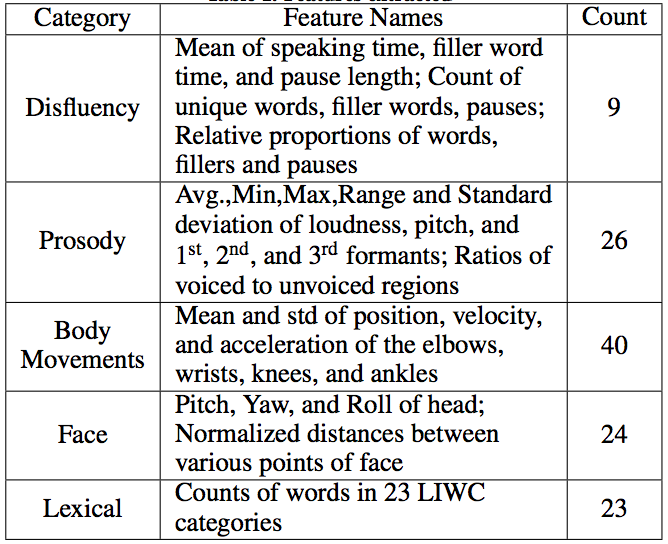
Five types of features are extracted from the audiovideo recordings: disfluency, prosody, body movements, facial, and lexical. We use linear classifiers to predict the annotations with AUC up to 0.82. Our results also shows that the way a speaker evaluates his/her own speech is different than the way an audience perceives it. Speakers tend to emphasize more on verbal aspects of the speech while the audience focuses on the non-verbal aspects.
For details, please read the papers.
M. Iftekhar Tanveer, Ru Zhao, Kezhen Chen, Zoe Tiet, M. Ehsan Hoque, AutoManner: An Automated Interface for Making Public Speakers Aware of Their Mannerisms , Proceedings of the 21st International Conference on Intelligent User Interfaces (IUI), April, 2016.
M. Iftekhar Tanveer, Ru Zhao, M. Ehsan Hoque, Automatic Identification of Non-Meaningful Body-Movements and What It Reveals About Humans arXiv preprint arXiv:1707.04790, 2017